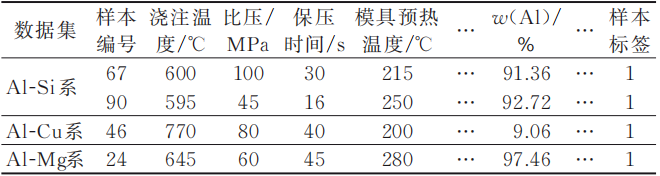
.jpg) 原标题:融合领域知识和集成模型的挤压铸造工艺数据正确性检测方法 当前,数据驱动科学正成为继试验科学、理论推导和模拟仿真之后的第四范式,数据驱动方法成为各领域新的发展基础和方向。材料领域研究者正通过利用以往的试验数据实现新材料的快速设计,有效解决传统试验研究模式存在的周期长、成本高等问题,在制造领域数据驱动制造也成为实现智能制造的一条路径。但数据驱动方法的性能严重依赖于其驱动数据样本的质量(正确性、一致性、低缺失等),较差的数据质量不仅导致错误的知识获取,影响数据驱动模型、方法的正确性、学习效果和有效性,甚至可能造成严重后果和巨大损失,如基于有错误数据的数据样本训练得到的机器学习预测模型,预测结果与实际差异过大,无法应用;据统计,较差的数据质量甚至造成了美国零售企业平均每年超过1 500万美元的损失。 挤压铸造是一种融合了铸造和锻造优势的零件近净成形制造工艺。为了适应智能制造的发展趋势,需要基于已有工艺数据建立数据驱动的工艺参数设计方法,解决当前工艺参数依赖“试错法”设计成本高、效率低等问题,从而提高挤压铸造工艺的生产效率和制件质量。数据驱动方法依赖的工艺数据可来源于物理试验或数值模拟试验记录、理论计算、工业生产和已有文献等,但因生产环境、试验方案、测量手段等存在差异,以及数据采集、记录和发布过程中的误操作等因素,不可避免会导致从多源渠道收集到的挤压铸造工艺数据彼此间存在冲突,或与真实数据有一定误差,即某些数据可能存在异常或不正确,如有关研究均采用物理试验的方法开展AZ31镁合金挤压铸造工艺参数优化研究,但得出挤压压力和保压时间的最优值分别相差50 MPa和20 s。为保证构建的挤压铸造数据驱动工艺参数设计模型的质量,对其依赖数据进行有效的正确性检测,进而清洗或提升至关重要。 为了实现数据驱动应用,通常从不同渠道收集数据或采用不同的数据增强算法来产生新的数据,但这些数据的质量良莠不齐。当前,不同领域研究者逐渐意识到数据质量的重要性,并采用基于统计分析、聚类、基于密度、最近邻等异常检测技术来评价数据正确性,以识别和剔除(清洗)异常数据,从而获取对象的正确认识、知识和模型等。主要出现了基于密度的局部离群因子(Local Outlier Factor ,LOF)、基于隔离思想的孤立森林算法(Isolation Forest,IForest)和基于统计分析的箱型图(Boxplot)等典型的数据异常(即不正确的数据)检测方法。LOF由BREUNIG M M等首次提出,其核心思想是数据点异常与否取决于局部环境,即一个样本点所在位置的密度与该样本点周围的样本所处位置的平均密度相比,差距越大则越可能是异常点。LOF因其简单有效被广泛应用于现实场景下的异常数据检测,如工业过程故障检测、网络入侵检测等。研究者采用LOF算法对工业过程异常数据进行检测,并利用CDC(Closest Distance to Center)采样点预处理方法,数据仿真表明其效率有所提高,可满足该领域的实时性要求。针对多工况数据,采用LOF算法结合统计模量对故障样本进行检测,发现其检测率比主元分析(PCA)、核主元分析(k PCA)和基于k近邻等检测方法均更高。设计了一种基于LOF的检测方法用于识别网络攻击,并通过实例验证了该方法的可用性。基于LOF和DBSCAN(Density-Based Spatial Clustering of Applications with Noise)构建了一种网络入侵检测模型,经入侵试验证明其具有低误报率、高检测率的特性。此外,为提高LOF算法的异常检测效率,有研究者提出了融合谱角和LOF的SALOF(Spectral Angle and the Local Outlier Factor)算法,依据事先设置好的分割阈值筛选计算得到数据点的异常概率。通过设计融合索引结构和多层LOF上界的多粒度剪枝方法,提出了MTLOF(Multi-Granularity upper Bound Pruning Based Top-n LOF Detection)算法。IForest是由LIU F T等提出的一种无监督异常点检测集成方法,其利用异常数据普遍存在的“少而不同”的特点,将异常数据定义为容易被孤立的离群点进行识别,因其时间复杂度低、算法简单高效而广受关注,广泛应用于金融、医疗、网络安全和工业等领域。利用IForest算法同时对4种测度指标进行异常值识别,并根据多数投票原则,将2种以上测度同时出现异常值的样本视为极端系统性金融风险,实例说明该算法能够很好地适用于系统性金融风险分类。利用IForest算法对老年人的日常行为数据进行建模,以检测不符合正常行为模式的跌倒数据,通过公开数据集验证表明该模型的平均识别准确率可达96.76%。针对网格攻击中的拒绝服务攻击,将IForest算法应用于网络数据异常检测,具有较高的异常检测性能。将IForest算法应用于船用核电汽轮组系统级、设备级和参数级的异常数据检测与定位,其对每个异常状态的查准率超过94%。将IForest算法拓展到功能数据的异常检测,并通过数值模拟验证了算法的有效性和准确性。箱型图是一种用作显示一组数据分散情况的统计图,用于反映数据分布特征,由TUKEY J W首次提出。因其简单易用和良好的抗掩蔽效应性能,箱型图被广泛应用。将箱型图应用于构建数据预测模型的数据预处理阶段,过滤传感节点采集的异常数据点,发现经异常点过滤处理的预测模型预测精度提高了8.4%。 综上,现有数据异常检测通常只采用单一的异常检测方法对数据样本进行检测,但单一异常检测方法只能获得数据集上单角度的测度,泛化能力不足,适用场景有限。如IForest方法虽然无需数据先验知识,计算复杂度低,但其设计原理决定了该方法只适用于低异常程度的数据集,对异常数据比例较高的数据集则效果不佳,同时其结果不够直观和易解释;基于密度的LOF方法虽然结果可解释性好,但其性能严重依赖参数选择,且计算复杂度较高,处理高维数据集效果不佳。Boxplot方法具有非参数性,适用于任何类型的数据分布,且结果直观易比较,但其受数据量限制,当数据量很小时,结果往往不够精确。其次,单一的异常检测方法对所有数据均采用同一种异常评价标准,无法综合考虑数据的总体和局部信息,可能导致检测精度不足和效率不高等问题。如IForest方法异常检测过程均采用全局异常标准,对局部异常点检测效果不佳,而LOF方法则是通过计算给定数据点的局部偏差来识别异常点,拥有充分检测局部异常点的优势。再次,现有检测方法主要从数据分布特性出发对数据进行正确性检测,很少融入数据涉及的工程知识来帮助检测,导致难以发现有悖于领域知识的异常数据,如在挤压铸造工艺数据中,对液态挤压铸造,其浇注温度要高于金属的液相线温度,而对半固态挤压铸造,其浇注温度应处于固液相线温度之间,两者虽存在明确分界,但其数据分布可能相近,仅从数据分布特性出发则难以发现异常。 基于此,本研究面向挤压铸造工艺的数据驱动研发需求,为保证其依赖的多源、异构的工艺数据的质量,基于挤压铸造工艺特点,提出集成LOF、Boxplot和IForest算法,并融合挤压铸造领域知识的工艺数据正确性检测方法(LBI-Based Data Correctness Detection Method Incorporating Squeeze Casting Domain Knowledge, LBISCDK),该方法综合考虑不同异常检测模型的优缺点,并融合挤压铸造领域知识,从工艺数据本身和领域知识两个角度对挤压铸造工艺数据进行正确性检测,提高对异常数据的检查能力和检测效率,可为后续的数据驱动应用提供高质量的数据样本,保证数据驱动应用的质量。 图文结果 挤压铸造工艺数据主要包含工艺参数数据、工艺影响因素数据和铸件性能数据,其中工艺参数数据主要包括浇注温度、挤压压力、模具预热温度等,工艺影响因素数据主要由影响工艺参数的因素组成,包括材料成分和铸件形状特征参数等,铸件性能数据则由不同铸件的力学性能等组成,如硬度、抗拉强度等,对应类别在数据集都可称为属性。设建立的挤压铸造工艺数据集为DT,有n个样本,m个属性;Si(i=1,2,…,n)=1,2,…,(表示第i个数据样本);Aj为第j个属性;aij为第i个数据样本对应的第j个属性数据,则DT={aij|i=1,2,…,n,j=1,2,…m}其结构见表1。 表1 挤压铸造工艺数据集
(1)LOF模型 LOF主要聚焦于数据点的邻域密度,将数据视为空间中的点,具有低密度的数据点视为异常点。如在以两个数据属性为坐标轴形成的二维空间中(见图1),C1和C2为两个正常的数据点簇,点O1、O2为两个离群的异常数据,其数据密度明显不同。因此如果一个样本点的密度比较小,而它周围临近样本点的密度都比较高,那么其可能是异常点(见图1中O1)。在本研究中,将挤压铸造工艺数据的属性抽象为坐标轴,形成LOF中多维空间的工艺数据样本点。为检测其中的异常样本,则需要计算数据密度。构建的检测挤压铸造工艺数据正确性的LOF模型的伪代码见表2。
图1 含异常数据的二维数据集
图2 LOF示意图 表2 检测挤压铸造工艺数据正确性的LOF模型伪代码
(2)IForest模型 IForest是一种基于树结构的异常检测方法,由预设的多棵隔离二叉树iTree组成,其利用数据点被二叉树分割的次数来度量一个点是聚集(正常)还是孤立的(异常)。图3为随机分隔数据点。从图3a可知,对于数据集群中的正常点xi,需要对其进行多次随机分割才能隔离出来;而对于异常点Oi,见图 3b,仅需要对其进行几次分割就可以隔离出来。基于IForest的挤压铸造工艺数据正确性检测过程主要分为训练和评估两个阶段,见图4。训练阶段生成指定数目的孤立树,其伪代码见表3。
图3 随机分割数据点
图4 IForest异常数据检测示意图 表3 IForest训练生成指定数目的孤立树
(3)Boxplot模型 通过箱型图(Boxplot)可以直观了解数据的集中趋势、离散程度和异常值情况,将异常大或异常小的极端值识别为异常值。图5为箱型图示意图。下四分位数Q1、上四分位数Q3分别指一组属性值按从小到大顺序排列后,处于25%、75%位置的数值,四分位距定义为IQR=Q3−Q1,各属性上边缘为Q3+1.5IQR,下边缘为Q1−1.5IQR,将超过上下边缘区间的数据识别为异常值,标记为1,其余正确数据标记为0。基于以上原理,构建的检测挤压铸造工艺数据正确性的Boxplot模型的伪代码见表4。
图5 箱型图示意图 表4 Boxplot算法伪代码
如前所述,以上3种模型各有优势,为了提高模型的泛化检测能力,采用集成学习策略,将以上3种模型视为单元模型进行集成。由于以上3种单元模型的输出均为数据样本的分类标签,故采用投票法进行模型集成,综合得到一个分类结果,即当两个及以上基础模型均判定某个挤压铸造工艺数据样本为异常时,则判定该样本最终为异常。设LOF、IForest和Boxplot模型的输出标记分别为y1、y2和y3,其输出都是1或0,集成输出结果y可表示为:
基于以上方法原理,提出融合领域知识和集成模型的挤压铸造工艺数据正确性检测方法LBISCDK,该方法流程见图6。检测过程大致分为3步: (1) 校验材料成分取值及判断样本材料系列 首先运用材料成分属性值取值规则对样本的材料成分数据进行检验,确保材料成分数据的正确性。对于材料成分数据取值合理正确的样本,通过比较合金成分中除主元素(如Al)外的其他元素的质量分数,取最大值判定数据样本所属材料系列,如一条数据样本的Si元素质量分数为除Al元素外的最大值,则判定该样本为Al-Si合金的挤压铸造工艺数据,并自动选择Al-Si合金系列的属性值取值规则和集成模型。 (2)基于领域知识的正确性检测 基于对应合金系列的工艺数据属性值类型、经验取值范围对样本数据进行检测,如果样本数据属性值类型相符且数值在经验取值范围内,那么将其标记为正常样本并进入下一步检测;否则将其标记为异常,结束检测。 (3)LBI集成模型检测 通过第二步检测的样本再应用集成模型LBI进行检测,输出相应结果标签。
图6 LBISCDK方法检测流程 试验真值数据为本研究从CNKI、Web of Science等数据库检索的挤压铸造相关文献中提取整理的4个不同系列铝合金(Al-Si系、Al-Mg系、Al-Cu系和Al-Mg系合金)的近液相线温度挤压铸造工艺数据集,共332个样本,其中每个样本包含4个工艺参数属性(浇注温度、挤压压力、保压时间和模具预热温度)、5个铸件几何特征属性(挤压方式、形状复杂度、最大壁厚、最小壁厚和材料成分)和3个质量指标属性(抗拉强度、屈服强度和缩松缩孔率),见表5。对表5的工艺数据真值数据集通过生成随机异常偏移量来进行异常数据模拟添加,并通过设定异常数据比例来实现生成不同异常程度的待测数据集,算法的伪代码见表6。 通过在收集的铝合金近液相线挤压铸造工艺数据真值数据集中随机加入其他材料成分(如Cu合金、Mg合金等)或其他工艺方式(如半固态挤压铸造等)的工艺数据样本,以模拟在数据收集和整理过程中因操作失误而导致数据异常的情况。经过异常数据模拟添加后得到4个不同异常程度的异常数据集,见表7。真值数据集和异常数据集的4个关键属性的数据分布见图7。可以看出,相较于真值数据集,由于异常数据的存在,异常数据集中各属性的数据分布范围变大,即有异常数据超出原正常数值范围。 表5 挤压铸造工艺真值数据
表6 随机异常数据模拟添加算法伪代码
表7 异常数据集详细信息
图7 工艺数据集关键属性的数据分布 校验材料成分数值步骤,发现Al-Zn系合金数据集中样本37的材料组分数值之和为102.46,其违反材料成分属性取值规则且明显不符合工程实际。基于挤压铸造工艺数据属性值的取值范围、数值类型等信息对数据样本进行正确性检测,发现4条异常样本(见表8,其中标签0代表正常,1代表异常),其中Al-Si系合金数据集的样本67和样本90的浇注温度数据偏离Al-Si合金的经验取值范围,核实数据源文献发现其为半固态挤压铸造工艺而非近液相线温度挤压铸造。Al-Cu系合金数据集中样本46的浇注温度数据偏离经验取值范围,Al材料成分数值也明显异常,核实数据源文献发现其为AZ91D镁合金的近液相线温度挤压铸造工艺数据。Al-Mg系合金数据集中样本37的浇注温度数值偏离经验取值范围。删除违反属性值取值规则的数据样本,然后将其余数据样本采用LBI集成模型进行二次检测,得LBISCDK方法的检测结果见表9。对相同数据集,只使用LBI集成模型的检测结果见表10。 表8 违反属性值取值规则的异常样本
表9 LBISCDK方法检测异常样本
表10 LBI方法检测异常样本
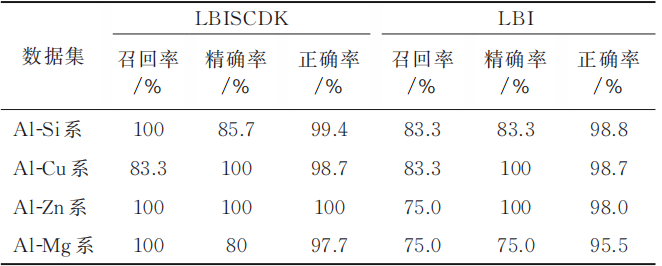
融合领域工程知识的LBISCDK方法和纯数据驱动的LBI方法各检测指标结果见表11。分析表11可得,LBISCDK方法在4个不同异常程度的异常数据集上的检测召回率、精确率和正确率的平均值分别为94.43%、95.23%和99.37%,其中Al-Zn系合金数据集的3个检测评价指标均为100%,说明该方法能够有效检测挤压铸造工艺数据集中的异常数据,检测效果可满足数据驱动相关应用需求。 图8为几种方法融合领域知识前后在4个异常数据集上的平均检测召回率、准确率和正确率。可见相较于纯数据驱动的检测方法,融合领域知识后的方法检测效果均有一定提升,异常数据召回表现尤其优秀;其中LBI、LOF和IForest方法的平均召回率分别提升了10.43%、1.58%和4.75%,LOF和Boxplot方法的平均精确率分别提升了2.68%和4.57%,Boxplot方法的平均正确率提升了5.6%,表明领域知识和数据驱动相结合能够对挤压铸造工艺数据集中的异常数据进行更加有效的识别,可为数据驱动的挤压铸造工艺参数设计等数据驱动应用提供高质量的数据样本。 表11 异常检测结果
图8 几种方法融合领域知识前后的检测效果对比 结论 (1)数据驱动方法的准确性和有效性严重依赖于正确、高质量可靠的数据样本,在数据驱动应用前对数据样本进行正确性检测和提升至关重要。现有数据正确性检测方法往往仅采用单一模型从数据特性检测,忽视了工程知识,无法有效检测出有悖于工程知识的异常数据。 (2)面向数据驱动的挤压铸造工艺参数设计方法对数据质量的需求,提出了融合挤压铸造工程知识和多个模型的数据正确性检测方法。该方法将多源挤压铸造工艺数据的正确性检测划分为两个阶段,第一阶段使用挤压铸造工程知识构建工艺数据属性取值规则,识别背离工程知识的异常数据,第二阶段从数据维度出发,根据数据特征使用LOF、Boxplot和IForest 3种模型来优化检测,实现了3种方法优势互补,提高了3种方法的泛化能力。 (3)实现了知识和数据特征双维度检测,拓展了数据异常(正确性)检测的维度,为数据清洗等应用提供了新的参考视角,其中的集成模型可以单独用于其他数据集异常检测。试验表明,所提方法提高了异常数据的检测召回率、正确率,对异常数据的召回率平均可达95%。 《融合领域知识和集成模型的挤压铸造工艺数据正确性检测方法》
邓建新1,2 吴秀松1,2 李修明3 尹政1,2 本文转载自:《特种铸造及有色合金》 |
.png)
.png)
.png)
.png)
.jpg)
.jpg)

.png)
.png)
.png)
.png)
.png)
.png)
.jpg)
.png)
.png)
.png)
.jpg)


.jpg)